Content Analysis Project using LDA topic modeling
LDA on 16 interview of both first and last year UCSC first generation students
This post is about the Qualitative Data Analysis class that I took at the department of education, UC Santa Cruz. The project objective was to develop two sets of interview protocols for first generation first year and last year undergraduate students at UCSC. The main objective of this project was to understand the lived experiences of first generation college students during their transition into and out of their undergraduate experience at a public research university.
During this project 16 interviews, 9 with first year and 7 with last year with UCSC undergraduate students were conducted and transcribed. My contribution to this project was to run LDA topic modeling on the 9 first year, 7 last year and 16 all UCSC transcribed documents.
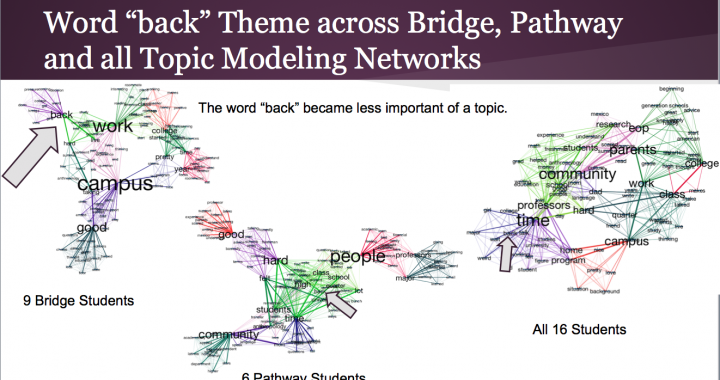
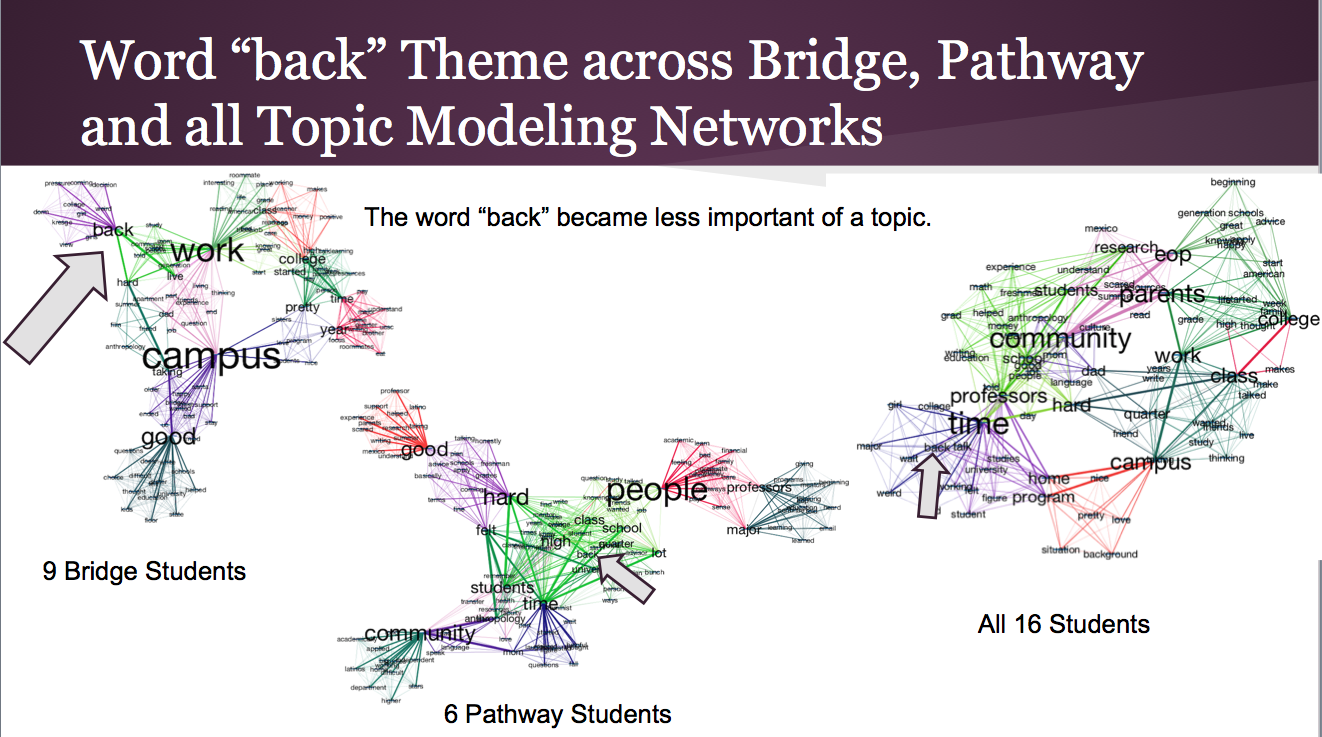
Looking at these three graphs generated by running LDA through mallet and then feeding cytoscape with .graphml file, we quickly realize that the larger the size of the word, the higher betweenness centrality it has. Betweenness centrality means number of shortest paths from al vertices to all others that pass through that particular node. For example, the word community is one the largest words in the left picture. That means it is an important word that appears in most of the topics. And the heavier the edge is between two vertices means those words happen to co-occur in a topic. As we can see, the larger a word is, the heavier the edges to it are. This makes sense because of the betweeness centrality of the larger words.
Now, how to really get benefit from the graphs generated above? Well, the best way is to start off by performing content extraction around the words with large size. For example lets pick the word “back” that happens to have a higher betweenness centrality in the topics extracted from first year students’ transcribed interiews.
To make sense out of this phenomena, one can infer that first year students were referring a lot to where they were coming from. “Back” were mostly meant to them “back home” or “going back home” or “giving back” to people from the community the came from. There were cases were back meant “back to back classes”. Overal first year students conversations were mostly evolved around where they were coming from and what differences they are experiencing in the new environment. However, the last year students were less focused on “back home”. To put this into perspective, I started to extract every sentence that had the word back in each document. Then started to cluster them and extracted the overall themes of each cluster.
In the picture above, you see the a few quotes that represent the major themes of first year and last year students.
Here is the set of slides of the class project: FGC Student Presentation
very nice